Platform over productie- en procesautomatisering

Recente evoluties in de ontwikkeling van microchips verruimen de mogelijke toepassingen van machine learning (ML) en zelfs deep learning (DL). Het schatten van moeilijk meetbare machinetoestanden is al tientallen jaren een probleem voor ingenieurs. Onderzoek toont aan dat, gebruikmakend van de modernste data-gedreven technieken, machine monitoring op een effici.ntere manier kan worden gerealiseerd. Door een case studie uit het TETRA project WearAI aan te halen, is de meerwaarde van classificatie algortimes duidelijk aantoonbaar.
De toepassing van geavanceerde signaalverwerkingsmethoden bij de bewaking van essentiële processen wordt beschouwd als een zeer interessant gebied met veel potentieel. Materiaalkosten worden verlaagd door het monitoren van anomalieën en meer productie is mogelijk door de berekende RUL toe te voegen aan onderhoudsschema’s. Het resultaat is een verhoging van de efficiëntie.
In het verleden was het opstellen van procesmodellen een complexe taak van lange duur. Personeel met diepgaande proceskennis gaat vaak van start met de ’first principles’ methode. Door hun kennis en ervaringen te combineren met fysische wetten is het mogelijk om kenmerken te beschrijven en zo tot een acceptabel model te komen. In de systeemidentificatie staat dit ook wel gekend als een white-box model. De interne structuur is volledig gekend.
De procesindustrie is constant in verandering en systemen worden alsmaar complexer. Meer actuatoren, sensoren, setpoints, grenswaarden, etc. maken de white-box benadering tijdsintensief. Daarom wonnen grey-box en blackbox technieken de laatste jaren terecht veel terrein. Beide gebruiken gecapteerde data om informatie over het proces inwinnen om het model nauwkeuriger te maken. Greybox modellen hebben nog steeds een white-box structuur, gebaseerd op fysische wetten, maar de parameters in de vergelijking worden geschat en iteratief aangepast om predictieve onnauwkeurigheden te minimaliseren. Black-box modellen hebben deze vooropgestelde structuur niet en worden volledig door bijvoorbeeld machine learning technieken bepaald. Zowel de structuur als de parameters zijn gebaseerd op de informatie geleerd uit de dataset. Door deze datagedreven aanpak versnellen we de ontwerpfase aanzienlijk.
De doelstelling van de casestudie is het ontwerpen van een data-gedreven algoritme dat de machineoperator kan inlichten over de staat van de onderdelen in een machine of een systeem in zijn geheel. Als voorbeeld halen we een case studie aan die in het TETRA project WearAI werd uitgewerkt. Het betreft het frezen van laminaat bij een partner met meer dan 60 jaar ervaring en behoort tot de grootste vloerenproducenten ter wereld. De harde kunststoffen toplaag van laminaat is de voornaamste bijdrager aan slijtage aan het snijgereedschap. De hoge voedingsnelheden en toerentallen garanderen vlotte productieprocessen, maar dit versnelt ook de degradatie van het gereedschap waardoor regelmatige stilstanden noodzakelijk zijn om ofwel de beitels te draaien of ze te vervangen. Gepland onderhoud minimaliseert uitval door snijkanten van lage kwaliteit, maar benut de volledige levensduur van snijgereedschappen niet. Onderhoud gebaseerd op de huidige gereedschapsconditie is de volgende logische stap in dit proces. Door een extern systeem bij originele machine te plaatsen werden datastromen gegenereerd zoals trillingen, akoestische emissies, stromen en spanningen. Waardevolle informatie voor verdere analyse en training van machine learning algoritmes. Door de afwezigheid van labels is het aangewezen unsupervised learning methodes te onderzoeken, zoals hier meer specifiek het DBSCAN algoritme.
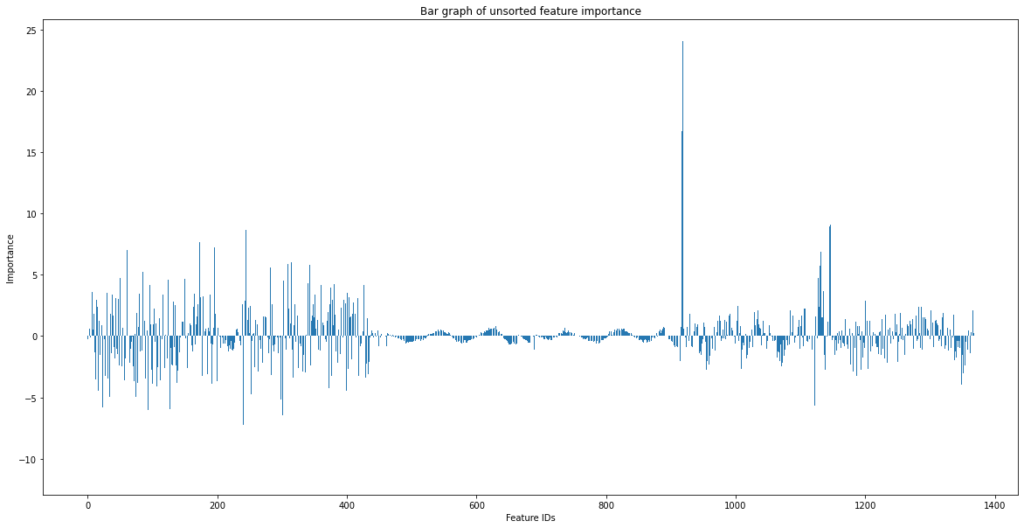
Na het extraheren van de gewenste features uit de gecapteerde datastromen is feature selectie een interessante (vaak onderschatte) tussenstap. Verschillende filters zijn noodzakelijk om uitschieters, ruis, het datadomein, etc. gestandaardiseerd te krijgen. Uit de vele gegenereerde features, in dit geval waren dit er 1360, mogen enkel de meest waardevolle features door naar de volgende ronde om dan uiteindelijk als trainingsdata dienst te doen. De originele dataset komt overeen met een run-to-failure experiment. Eigenschappen over de volledige gereedschapslevensduur zijn dus aanwezig. Door de set in 40 verschillende bins onder te verdelen, bevat elke bin informatie over ongeveer 2,5% van de levensduur. Met behulp van deze labels is het mogelijk om een eenvoudige lineare regressor te trainen. Door de nauwkeurigheid van het volledig getraind model te gebruiken als benchmark laten we stelselmatig features weg uit de trainingset en vergelijken de score. Op deze manier geven de verschillen in nauwkeurigheid een indicatie van het aandeel van een bepaalde feature. In grafiek 1 zien we alle features (weergegeven op de x-as) en hun ’impactsfactor’ op het correct identificeren van een bin.
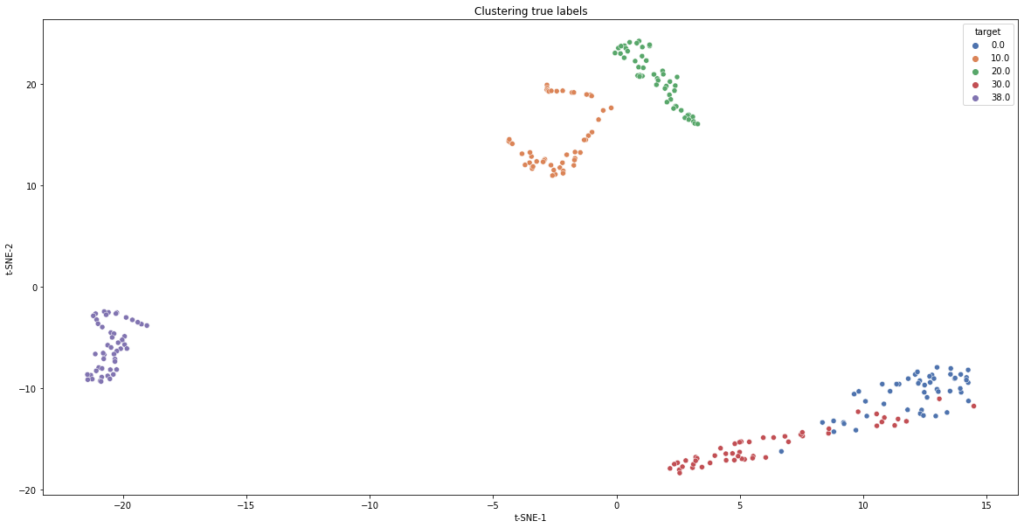
Idealiter houden we significante features over die de verschillende bins representeren met unieke eigenschappen. Om deze multidimensionale dataset visueel weer te geven kon t-SNE worden ingezet. Door de originele ruimte om te zetten naar waarschijnlijkheden, reduceert het 59 dimensies naar slechts 2 dimensies. Wat ideaal is om grafisch weer te geven. Op figuur 2 zijn 5 bins zichtbaar door hun verschillen in kleur. Bemerk dat twee bins gedeeltelijk gemengd zijn, wat latere classificatie kan bemoeilijken.
Nu we enkel de meest belangrijke delen uit de dataset overhouden, is het tijd om te beslissen welk model geschikt is. Door zijn ’unsupervised’ karakter gepaard met relatief weinig afstelparameters was Density Based Spatial Clustering Application with Noise (DBSCAN) een logische keuze. Bronnen uit de literatuur geven goede resultaten bij een gelijkaardige implementatie van deze techniek voor gereedschapsslijtage. Een belangrijke afstelwaarde is de gemiddelde afstand tussen ’normale’ datapunten (ε). Het genereren van de puntenwolk en enkele iteratieve calculaties geven ons de volgende gegevens.
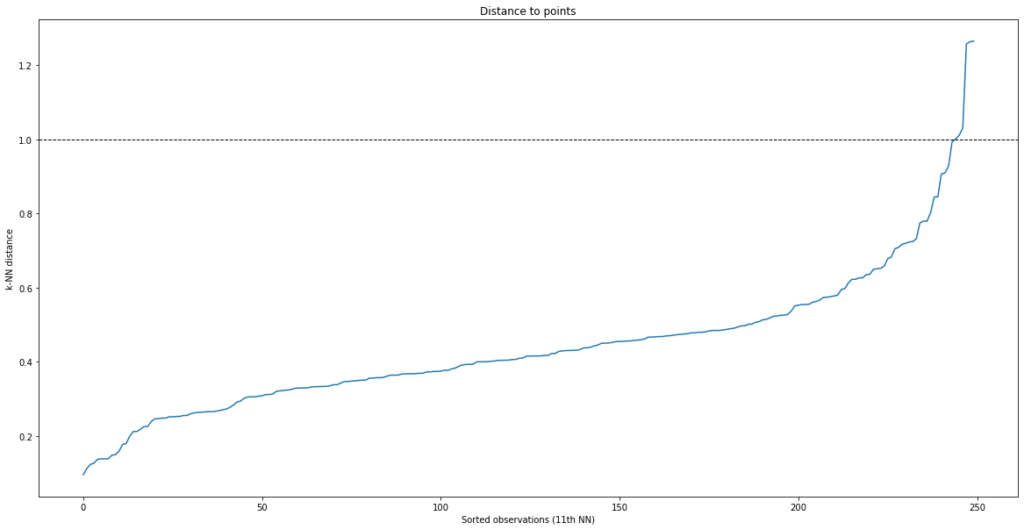
Uitschieters en ruis hebben grotere afstanden tegenover punten die behoren tot een cluster. Daarom kiezen we ε kleiner dan deze piek wat in dit geval neerkomt op een waarde ongeveer gelijk aan 1. Door dit in het DBSCAN algoritme toe te voegen zijn we in staat clusters te herkennen zonder zelf informatie te geven over het proces.
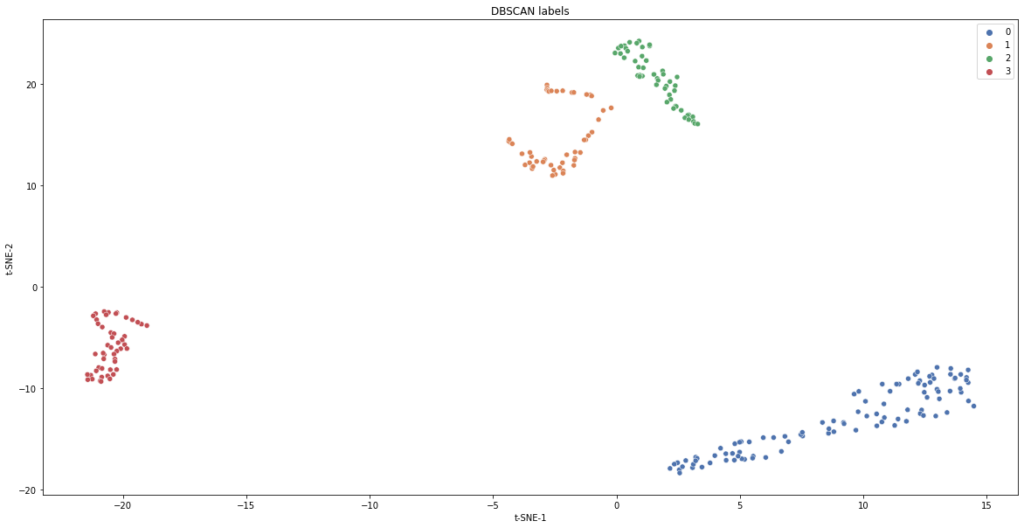
Het DBSCAN model is duidelijk in staat om verschillende clusters te onderscheiden. Rechtsonder op figuur 4 zijn twee bins samengevoegd tot één cluster. Omdat de informatie van deze datapunten tijdens het midden van de levensduur werd opgemeten, kunnen we concluderen dat er minder variantie is tussen deze bins met betrekking tot bins tijdens de break-in of eind fase van de gereedschapslevensduur. Een conclusie die gelijk loopt met voorgaande experimenten en klopt volgens de machine operatoren.
De gevolgen van het implementeren van ML/DL in bestaande machines zijn niet te onderschatten. Dit uitgewerkt voorbeeld bevat geen informatie over ML deployment, maar toont duidelijk aan dat regio’s van break-in en versnelde slijtage te onderscheiden zijn met behulp van unsupervised machine learning algoritmes. Hierop verder werkend zijn systemen in een industriële context die catastrofale breuk kunnen voorkomen. Wat opnieuw een directe factor is in het minimaliseren van downtime, wat op zijn beurt productie verhoogt. Door het verhoogde inzicht in de machineconditie is de stap naar conditioneel onderhoud mogelijk wat opnieuw downtime verlaagt en operatietijd per gereedschap verlengt. Meer productie-uren per tool vertaalt zich naar minder stock en minder daarbij horende stockkosten.
Data-gedreven technieken zijn niet zomaar het laatste nieuwe technologische stokpaardje. Het is een verschuiving in visie en perspectief. Het past perfect in de Industrie 4.0 filosofie en elke organisatie die dit pad wilt volgen, moet een zorgvuldige structuur uitbouwen. Het is geen enkelvoudig project, maar een transitie naar een data gecentreerde aanpak. Het zal elk bedrijf met een gezond data management systeem een stap dichter brengen bij predictief onderhoud en slimme datauitwisseling.
Door aan te tonen dat zelfs relatief eenvoudig modellen in staat zijn bijvoorbeeld een breuk te signaleren, is de slagkracht en het potentieel van deze aanpak duidelijk. We zijn overtuigd van het potentieel en kijken ernaar uit om dit uit te breiden naar andere toepassingen.
Graag bedanken we dr. Tim Claeys en prof. dr. ir. Jeroen Boydens voor steun en toewijding in dit project. Projectmedewerkers Hans Naert, Pieter Ideler, Peter Vanbiervliet en Robin Loicq waren onmisbaar bij de data captatie en de communicatie naar de industriële partners.
Louwers Mediagroep
Domein de Herten
Hertsbergsestraat 4
8020 Oostkamp, België



